存储器层次结构 - CS:APP 第六章
本章的主要内容有四:
- 介绍存储技术
- 介绍存储器的层次结构思想
- 特别介绍高速缓存的原理和细节
- 使用局部性优化程序的性能
本文主要介绍前三条内容,第四条内容可以说是优化程序性能的一部分,所以本文暂不深入。另外,本章和第九章虚拟内存密切相关,因此本文也会介绍第九章的虚拟内存,来完整的总结计算机的存储系统。
1 存储器的层次结构
根据我们的经验观察,读取速度越快的存储器/存储技术,成本越高,容量越小,读取速度越慢的存储器,成本越低,容量越大。
因此我们可以将大量的数据都存放在成本低,速度慢的存储器上。
但随着技术的发展,CPU的时钟周期越来越快,如果让CPU直接和这些慢速存储器交互会浪费大量的性能,因此我们可以上速度快的存储器缓存低速存储器的内容,与CPU交互,这就是存储器层次结构的思想。
存储器层次结构的中心思想是,对于每个k,位于k层的更快更小的存储设备作为位于k+1层的更大更慢的存储设备的缓存。
1 | L0 寄存器 |
下面我们介绍它们的存在基础,存储技术。
2 存储技术
我们要介绍的存储技术如下
- 随机存储器RAM
- SRAM
- DRAM
- 非易失性存储器 ROM
- PROM 可编程ROM
- EPRROM 可擦可写可编程ROM
- flash memory 闪存(基于EPRROM)
- SSD (基于闪存,固态硬盘就是使用SSD技术)
- 磁盘
2.1 随机访问存储器
随机存储器分为两种材类:SRAM和DRAM
SRAM 静态随机存储器,通电之后,数据就是稳定的,因此被称为静态随机存储器。速度最快,造价高,一般计算机的高速缓存是SRAM。
DRAM 动态随机存储器,其原理是电容充电,DRAM上的单元在10 ~ 100ms 内就会放电,所以要定期刷新以保持数据,因此被称为动态随机存储器。速度相对SRAM慢,造价相对低,一般用于计算机的内存 或叫做主存。
2.1.1 DRAM / 内存的工作原理
内存由若干个DRAM芯片构成,被称作内存模块(memory module)
每个DRAM芯片由超单元矩阵、内部行缓冲区、内存控制器构成,DRAM芯片上还有由于信息输入输出的脚针。
每个超单元内存储若干个位,一般是一字节八位。
1 | 内存/主存 |
首先介绍DRAM 芯片:

DRAM 芯片由超单元矩阵、内部行缓冲区、内存控制器构成。一个DRAM芯片中由d个超单元,这些超单元被组织成 r 行 c 列的长方形矩阵(r * c = d),每个超单元内存储w位,我们称这是一个d×w的DRAM芯片。
我们可以看到两个引脚,一个addr引脚向内部输送行列信息,一个data引脚向外输送存储在一个超单元上的位。一个超单元有多少位,data引脚就有多少位。
接下来看一下工作流程:
首先内存控制器在addr引脚上发送行地址,DRAM将相应的一行放到内部行缓冲区上作为相应,接着内存控制器在addr引脚上发送列地址,DRAM将内部行缓冲区上的列放到data引脚上传输出去 作为相应。
接着介绍内存模块:

一个内存模块由若干个DRAM芯片构成,当内存控制器给内存模块发送一个行列信息(i, j) 时,内存模块会将它所有的DRAM芯片上(i, j)位置的超单元的位 取下来,将所有的这些字节拼成一个字,再传输出去,如上图所示。
2.2 磁盘 & ROM
ROM可分为
- PROM 可编程ROM
- EPRROM 可擦可写可编程ROM
- flash memory 闪存(基于EPRROM)
我们不多介绍,只需要知道他们的名字和依赖关系即可
磁盘:通常指的是机械硬盘,也不过多介绍。
3 高速缓存
首先我们补充存储器层次结构方面的知识,由于这部分知识和本节密切相关,因此我们放到这里介绍:
对于存储器层次的k+1层,该层的存储器被分为连续的数据对象组块(chunk),称为块(block),块的大小通常是固定的。
而第k层的存储器被划分为较少的块的集合,每个块的大小与k+1层的块的大小是一样的,在任意时刻,第k层的缓存包含第k+1层块的一个子集的副本。
- 数据总是以块大小为传送单元,在第k层和第k+1层之间来回复制,虽然在层次结构中的任意一对相邻的层次之间块大小是固定的,但是其他层次对之间可以有不同块大小。
以上是书上的原话,他们介绍了一个重要的概念——块。你要记住在层次之间传送的是块。
令人迷惑的是第三句话,相邻层次的块大小是相同的,但隔层之间的块可以是不同的。如果相邻层之间的块,大小是相同的,那么所有层次的块,大小都应该是相同的。
这句话暂且悬置。
当然,硬要解释也是可以的,你可以理解为,相邻块之间总是传输大小相同的单元,但下层块一旦到了上层,就会被划分为更小的块,用于与上层交互。
但最好还是理解成所有块的大小都是相同的,方便理解下面的内容。
3.1 高速缓存的结构

一个计算机存储器的地址有m位,他被分为三部分:
- 高t位是标记位
- 中间s位是组索引位
- 低b位是组偏移位。
高速缓存被组织为这样的结构:
高速缓存有2^s^ 组,每组被编号位0,1,2,…,2^s^ - 1
每个组中最多有2^t^ 个高速缓存行
- 每个高速缓存行也由三部分组成
- 一位有效位,标记着这个高速缓存行是否有效
- t个标记位,用于与该组中的其他高速缓存行区分,因此每组只能由2^t^ 个高速缓存行
- 2^b^ 大小的数据,存储的是在下一层复制上来的块(block),一行就存储了一个块的内容,有时候,“行” 和 “块” 这两个术语可以交替使用
3.2 高速缓存的工作原理
当CPU向高速缓存发起读指令时,高速缓存首先确定缓存是否命中,如果命中,直接发送给CPU的寄存器。如果不命中就向主存取,等待数据到达某个高速缓存行,接着发送给CPU的寄存器。
确定是否命中有三个步骤:
- 组选择
- 行匹配
- 字抽取
组选择
回忆我们的地址的中间s位是组索引,所以我们只要抽取组索引就可以找到对应的组,而且由于一共有2^s^ 个组,所以,组一定会命中。
行匹配
如果一个组里的某一行,改行的有效位被设置,且标记位等于地址的标记位,则行匹配成功。
如果行不命中,就要牺牲某一行,将它驱逐,相应的块从低层次的存储层次中取上来。
补充 :
我们先回忆一下地址的构成
标记位 t + 索引位 s + 偏移位b
假设有一个四位的地址,t = 1,s = 2,b = 1
这四位地址的所有组合如下:

我们把目光投向一对缓存层,由于地址的限制,较低层有8块,而较高层有4组(这里的4组是我们规定的)。
我们的低层有8块,高层有4组,对于低层块如何在高层放置,我们做出如下规定:对于低层的块i,它必须存放在高层的 i mod 4 组上。
这样我们较低层的 0、4 映射到了较高层的0组,
1、5映射到了1,
2、6映射到了2,
3、7映射到了3
一个组中可以有最多2^t^ 行,如果我们一组中只有一行。
如果我们首先引用了块0,那么块0每放在较高层的组0,
接下来我们再引用块4的时候,由于我们规定一组只有一行,这时就出现了一个冲突,我们必须选择一个牺牲行,来放置块4,在这里毫无疑问我们将选择唯一的一行。我们将块4放到了组0的唯一一行。
通过上面的例子,我想说明两点
一、并不是所有组都只有1行,如果一个组有多行,如果出现上述情况,我们只能使用严格复杂的策略去选择牺牲行,或者直接随机选择一个牺牲行。
二、如果我们获得了一个地址,这个地址的组索引是0组,但该组里并没有一个有效的标记与我们地址的标记匹配,这是我们要怎样在下层存储中找到我们要得到的块呢?
注意到,将地址的标记位(1位)和组索引位(2位),合起来(3位),刚好是块在较低存储层的编号。这样就可以快速在较低层定位块。
其实,将地址分成标记位和索引位,并不能扩充地址空间的大小,但可以增快寻址速度,这一点就是利用了这个原理。
- 字抽取
只要根据地址中的块偏移定位到行的某个位置,就可以取出在此之后的任意长度的位。
4 虚拟内存
从上面的叙述我们可以看出,计算机的存储系统是复杂的。为了简化内存管理,现代系统提供了一种对主存的抽象概念,叫做虚拟内存。它为每个进程提供一个大的、一致的私有地址空间。
虚拟内存提供三个重要的能力:
- 它将主存堪称是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它搞笑地利用了主存。
- 它位每个进程提供了一致的地址空间,从而简化了内存管理。
- 它保护了每个进程的地址空间不被其他进程破坏。
从上面的原文我们可以看出,虚拟内存是对磁盘的抽象,它管理的是磁盘上的块,按需要将磁盘上的块传送到主存DRAM中。同时我们要知道,虚拟内存将磁盘上的N个连续的字节大小的单元组织成数组,每个单元都有唯一的地址。
虚拟内存的存在基础:
同一个数据对象,它在不同的地址空间里可以有不同的地址,主存中的每一个字节都可以有一个选自虚拟地址空间的地址和一个选自物理地址空间的地址。
4.1 虚拟内存原理
首先介绍两个概念,我们知道,在两个相邻的存储层次,他们传输的是块(block),而在磁盘和主存中传输的块被称为页:
PP(Physical page) 物理页 : 在磁盘和主存之间传输的块
VP (virtual page ) 虚拟页 : 在虚拟内存系统中与物理页对应的块
真正的页就是物理页,而虚拟内存管理的页就是虚拟页,虚拟页和物理页是一一对应的,大小相等的。
我们知道,主存的容量远小于磁盘,而我们的虚拟内存是对磁盘空间的映射,所以,主存有时并不能放下某个进程的全部虚拟内存。而且,计算机要同时运行多个程序,不能只在主存中存放某个进程的虚拟内存。因此我们只能将某个进程暂时用到的虚拟内存的某部分存放到主存中。
4.2 虚拟内存的结构
在CPU上有一个名叫内存管理单元(Memory Management Unit)的硬件,利用存放在主存中的页表来动态翻译虚拟地址。
页表:每个进程都有一个页表,页表将虚拟页映射到物理页。

快表 (Translation Lookaside Buffer,TLB):在MMU中的对页表的缓存,因为页表存储在主存中,所以与同为主存的高速缓存一样,快表的结构也是组加行,寻址时,首先进行组选择,接着进行行匹配,最后字抽取。
4.3 虚拟内存的地址翻译
下面简单概括以下虚拟内存的地址翻译:
- 处理器产生一个虚拟地址,并将它传送给MMU
- MMU生成一个页表条目地址(Page Table Entry Address, PTEA),首先在快表中搜索该PTEA,如果快表命中,我们得到页表条目(Page Table Entry, PTE)转4,否则在页表中寻找该页表条目地址,转3
- 由于快表没有命中PTEA,所以我们在高速缓存的页表中寻找该PTEA,如果命中,那么我们得到页表条目转4,如果高速缓存中的页表没有命中,那么我们要向主存请求页表,再从新的页表中搜寻PTEA,然后得到PTE,转4
- 现在我们已经得到了PTE,PTE在MMU中被翻译成物理地址,如果该物理地址在高速缓存中命中,那么我们直接将数据发送给处理器。如果高速缓存没有命中,我们就要在主存中请求该物理地址。

下面我们介绍虚拟地址翻译中的一些细节:
什么是页表条目地址(Page Table Entry Address, PTEA),它是怎样被生成的?
要解答这个问题,首先我们要介绍虚拟地址的格式。
| 虚拟页号 VPN | 虚拟页偏移 VPO |
| —————— | ——————— |页表条目地址PTEA和虚拟页号VPN其实是同一个东西,两者没有区别。例如,VPN 0 选择PTE 0,VPN 1选择 PTE 1。
PTE 是什么,它的结构是什么?
PTE 是页表条目,他的结构是这样的
| SUP 有效位 | READ 有效位 | WRITE 有效位 | PPN 物理页号 (Physical Page Number) |
| ————— | —————- | —————— | —————————————————- |前三段是有效位,如果SUP有效位设置为1表示该页只能在超级用户(内核模式)下才能被访问,READ有效位设置为1表示该页可读,WRITE有效位设置为1,表示该页可写。
PPN 物理页号是什么呢?
让我们回忆以下我们在介绍高速缓存时用到的物理地址

如图所示,物理地址是由高t位的标记位,中间s位的组索引和低b位的快偏移 组成的。
而标记位和组索引合起来就是PPN。
而块偏移和虚拟地址的虚拟页偏移VPO是一样的
因此,地址翻译的时候,只需要将PTE中的PPN取出来,和VPO拼接起来就得到了物理地址。

快表TLB的工作原理是什么?
快表和高速缓存的原理是类似的,我们首先重新审视一下虚拟地址:
虚拟地址由VPN和VPO组成
| 虚拟页号 VPN | 虚拟页偏移 VPO |
| —————— | ——————— |而虚拟页号VPN又可以分为两部分:
| VPN | VPN | VPO |
| ——————- | ——————- | —— |
| TLB标记(TLBT) | TLB索引(TLBI) | VPO |TLB首先进行组选择,即使用TLBI来匹配TLB内的组,这是一定可以命中的,原因详见高速缓存。
接着进行行匹配,即匹配TLB组内标记和TLBT相同的行。这一步就不一定会命中。如果按照我们之前的模型,由许多个页表条目PTE,只要他们的TLB索引相同(或者说VPN对2^S^ 取模,得到的值相同。PS: 其实这和组索引相同 是同一的,因为对2^s^ 取模就是取TLB索引,在这里,s指TLBI的位数),他们就会被映射到同一个组。如果没有命中,那么我们只能去高速缓存里继续从页表里翻找页表条目PTE了。
5 高速缓存系统和虚拟内存系统的对比
高速缓存系统 是在主存DRAM 和高速缓存SRAM 之间调度的系统
虚拟内存系统 是在磁盘(机械硬盘 或 SSD) 和主存DRAM 之间调度的系统
存储在某个存储层,在存储层之间传输的单元叫做块(block)
在高速缓存SRAM中,它叫做高速缓存行,或者行
在主存DRAM中,它叫做块(block)
在虚拟内存系统中,它叫做页(page)
调度策略
高速缓存不命中,替换策略往往很简单,因为不命中的惩罚很小
DRAM不命中,替换策略往往很复杂,因为DRAM与磁盘的速度相差很大,不命中的惩罚很大
6 技术总结
在介绍3.2 高速缓存工作原理时,我们看到了索引位和标记位的使用。同样我们在4.3 虚拟地址的翻译中也看到了TLBT和TLBI的使用。在这里我们对这种技术进行抽象和总结。
有两个存储层次,较下层的存储层次容量大,速度慢,我们称之为B层,较上层的存储层次容量小,速度快,我们称之为A层,我们要使用A层来缓存B层的内容。
我们将B层想象成一个数组,我们用n位的地址来表示这个数组的每个位。

B层可以容纳 2^n^ 大小的位。我们将B层划分为 2^m^ 块,其中每块的大小为 2^o^ ,这样数组的前2^o^ 位为第一个块,接着2^o^ 位是第二个块,依此类推。而这些块一共有2^m^ 个。我们有n = m + o。
现在我们通过巧妙地在地址中间花了一道线,不改变地址本身的结构,将线性的地址划分成了一个又一个的块。

由于A层的空间有限,我们只能将B层的2^i^ 块映射到A层,我们要怎么去映射呢?
我们的方法是取出我们地址的前m位,去这m位的低i位,这低i位相同的块映射到同一组,而我们使用这m位的高t = m - i 位来作为标记,区分一组中的不同块。
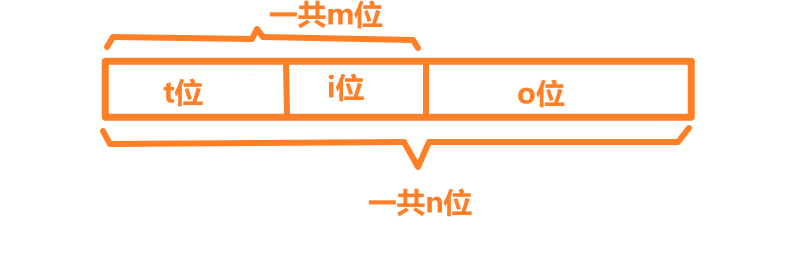
通过这种方式,我们就实现了将B层的块映射到A层,通过这种映射,只要我们知道某数据对象位于B层的地址,我们就能很方便的在A层找到它。
为什么使用中间位作为索引?
如果使用高位作为索引,连续的块可能会被映射到同一组,这样不能利用程序的局部性,造成比较大的损失。
接下来我们概括一下内存系统:
一个进程有自己的私有虚拟内存,它可以通过虚拟内存引用程序里的数据,io设备等。
如果他要引用一个数据,它生成一个虚拟地址,虚拟地址被CPU上的MMU转换成物理地址,然后依次开始在高速缓存、主存、磁盘 … 上寻址。
7 术语索引
主存储器(main memory 主存) : 即通常理解的使用DRAM内存。
块(block): 对于存储器层次的k+1层,该层的存储器被分为连续的数据对象组块(chunk),称为块(block)
VM (Virtual Memory) 虚拟内存
VA(Virtual Address) 虚拟地址
MMU(Memory Management Unit):内存管理单元,一种硬件
VP (virtual page ) 虚拟页 : 在虚拟内存系统中与物理页对应的块
PP(Physical page) 物理页 : 在磁盘和主存之间传输的块
页表 :一个数据类型位PTE的数组
PTE(Page Table Entry) 页表条目:存放在页表数组的每个元素的类型
页 : 在虚拟内存的习惯说法中,块(block) 被称为页。在磁盘和内存之间传送页的活动叫做交换(swapping) 或页面调度(paging)
缺页:DRAM缓存不命中称为page fault
内存映射:将一组连续的虚拟页映射到任意文件中的任意位置的表示法称作内存映射(memory mapping)。P566
快表 (Translation Lookaside Buffer,TLB):在MMU中的对页表的缓存,因为页表存储在主存中,所以与同为主存的高速缓存一样,快表的结构也是组加行,寻址时,首先进行组选择,接着进行行匹配,最后字抽取。